DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
Task Collaborative 3D Object Detection
method learn domain-invariant representation
inner thoughts distillation
摘要
车对物(V2X)协同感知最近获得了极大关注,因为它能够通过整合来自不同代理(如车辆和基础设施)的信息来增强场景理解能力。然而,目前的研究通常对来自每个代理的信息一视同仁,忽略了每个代理使用不同激光雷达传感器所造成的固有领域差距,从而导致性能不尽如人意。
也就是不同的LiDAR传感器本身的不同会导致一种domain gap,会使性能下降.这种说法看起来make sense,但加上一些示意图补充可能更好.这篇文章就加了一张.
提出了 DI-V2X,旨在通过一个新的蒸馏框架来学习领域不变表征,以减轻 V2X 3D 物体检测中的领域差异。
DI-V2X 包括三个基本组件:域混合实例增强(DMA)模块、渐进式域不变性蒸馏(PDD)模块和域自适应融合(DAF)模块.
具体来说,DMA 在训练过程中为教师模型和学生模型建立了一个领域混合三维实例库,从而形成对齐的数据表示.接下来,PDD 鼓励来自不同领域的学生模型逐步学习与教师领域无关的特征表示,并利用代理之间的重叠区域作为指导,促进提炼过程.
此外,DAF 通过校准感知领域自适应注意力,缩小了学生之间的领域差距.在具有挑战性的 DAIR-V2X 和 V2XSet 基准数据集上进行的大量实验表明,DI-V2X 性能卓越,超过了之前所有的 V2X 模型.
Introduction
它充分利用从不同代理(即车辆和路边基础设施)收集到的传感器数据,精确感知复杂的驾驶场景.例如,在车辆视线可能受阻的情况下,由于基础设施的视角不同,它们提供的信息可以作为重要的冗余.
与以往的单车自动驾驶系统相比,这种合作从根本上扩大了感知范围,减少了盲点,提高了整体感知能力.
为了有效融合来自不同代理的信息,领先的 V2X 方法倾向于采用基于特征的中间协作,即中间融合)。这种方法在特征层保留了每个代理的基本信息,然后对其进行压缩以提高效率。因此,中间融合确保了性能与带宽的权衡,优于早期融合或后期融合方法,前者需要在代理之间传输原始点云数据,而后者则容易受到每个模型产生的不完整结果的影响。
然而,当前的中间融合模型主要集中在增强来自不同代理的特征之间的交互。
如图 1(a)所示,车辆和基础设施可能拥有不同类型的激光雷达传感器,因此直接融合不同来源的点云数据或中间特征难免会影响最终性能。因此,在这种情况下,如何从多源数据中明确学习域不变表示仍有待探索。

为此,DI-V2X 引入了一种新的师生提炼模型.在训练过程中,我们强制要求学生模型(即车辆和基础设施)学习与早期融合的教师模型一致的领域不变表示法,即把来自多个视角的点云整合为一个整体视图来训练教师。在推理过程中,只保留学生模型。具体来说,DI-V2X 由三个必要组件组成:领域混合实例增强(DMA)模块、渐进式领域不变性提炼(PDD)模块和领域自适应融合(DAF)模块
其实基础思想就是蒸馏,搞一个结构相似但参数量更小的模型替代原本较大的模型. 关键是让小模型学会大模型的”知识”
DMA 的目的是在训练过程中建立一个mixed ground-truth instance bank,以对齐教师和学生的点云输入,其中的实例来自车侧、路侧或融合侧。
之后,PDD 的目标是在不同阶段,即在领域适应性融合之前和之后,逐步将信息从教师传递给学生.例如,在融合之前,引导学生在非重叠区域分别学习领域不变的表征。而在融合之后,我们将重点放在重叠区域内的提炼上,因为信息已经得到了很好的汇总.
在 DAF 模块中,来自不同领域的特征会根据其空间重要性进行自适应融合。此外,DAF 还通过整合校准偏移来增强模型对姿态误差的适应能力,从而确保 V2X 检测性能的稳健性。
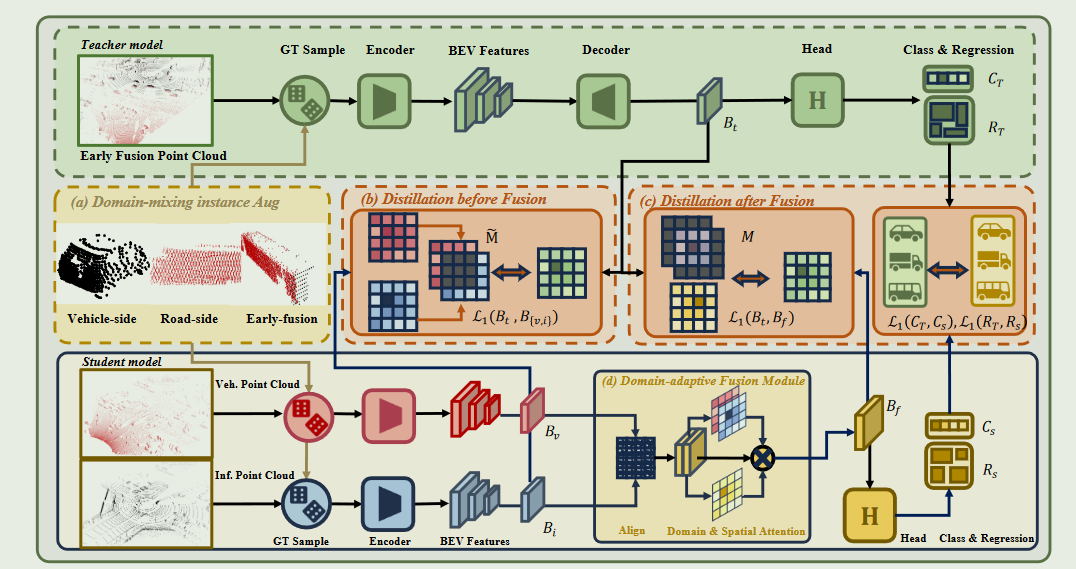
在DMA中,对于教师模型,使用车端数据,路端数据以及早期融合后的数据(就是转换到统一坐标系后的点云结果)利用PointPillars的decoder进行增强,使用增强后的\(P_e\),再使用VoxelNet处理成BEV的二维特征图\(B_t\).
学生模型结构跟教师模型类似,处理\(P_v\)和\(P_i\)提取得到对应特征图.然后使用DAF进行融合得到\(B_f\)
在训练的时候,在DAF融合之前和之后会有一个PDD模型将学生模型得到的特征和老师模型得到的特征利用overlapping area进行对齐.
DMA本是类似一个数据增强模块,首先将 \(P_i\) 投影到自我车辆的坐标系上,这样 \(P^T_i\) =\(T(i→v)\)\(P^T_i\),其中 \(T(i→v)\) ∈ \(R^{4×4} \)是基础设施到车辆系统的变换矩阵.然后,我们利用地面实况边界框 \(B_{gt}\) = {\(b_k\)} 从 \(P_v\) 和 \(P_i\) 获取实例.来自不同domain、对应于同一地面实况对象的实例将被合并,得到一个早期融合实例 pk = Concat(\(p^v_k\), \(p^i_k\)) ∈ \(R^{N_{k}×4}\),其中 \(p^v_k\)∈ Pv 和 \(p^i_k\)∈ Pi 是来自两个领域、以 \(b_k\)为索引的实例点。由于代理之间的相对位置会随着自我车辆的运动而发生动态变化,因此有些实例可能仅来自单个域,而另一些实例则可能直接来自早期融合的重叠区域。为了确定每个实例的域来源,我们通过计算来自每个域的点比例,将这些实例分为三类: $\( \begin{aligned} &D_{i} =\{\mathbf{p}_k|N_k^v/(N_k^v+N_k^i)<\tau_l\} \\ &D_{f} =\{\mathbf{p}_k|\tau_l<N_k^v/(N_k^v+N_k^i)<\tau_h\} \\ &D_{v} =\{\mathbf{p}_k|N_k^v/(N_k^v+N_k^i)>\tau_h\} \end{aligned} \)\( \)N^{v}{k}\( 和 \)N^{i}{k}\( 分别代表车辆侧和基础设施侧的点数,τl、τh 表示阈值.然后,得到一个实例库\)D_{mixed}\( = \)D_i\( ∪ \)D_f\( ∪ \)D_v\(,其中包含来自所有领域(即包括融合领域)的混合实例。在训练过程中,我们按照一定的概率从\)D_{mixed}$中随机抽取实例,并将这些实例添加给教师和学生.
通过涉及不同领域的实例增强了训练数据的多样性.此外,从每个学生的角度来看,来自其他领域的信息也会通过实例级混合被纳入其中(Zhang 等人,2018 年).这种方法从根本上调整了教师模型和学生模型之间的数据分布,从而在随后的知识提炼过程中产生了更具普适性的特征。
为了获得跟域无关的特征,采用了两阶段蒸馏策略,即在领域自适应融合(DAF)模块之前和之后进行蒸馏。第一个蒸馏阶段是将学生的分布与教师模型相一致,作为 DAF 的输入,这对准确的信息融合至关重要。
然而,根据经验发现,直接对学生和教师之间的整个特征图进行蒸馏会产生次优性能.为此选择在第一阶段对非重叠区域进行蒸馏.在第二阶段,由于学生特征已通过 DAF 得到很好的融合,我们可以集中精力对重叠区域进行蒸馏.这种两阶段的提炼过程可使学生模型与来自不同区域的教师模型的特征表示相匹配,从而缩小学生之间的差距.
在融合之前的蒸馏,首先需要计算重叠掩码,以确定重叠区域.
将基础设施一侧的感知区域转换到车辆一侧,得到一个新的矩形 \(A_i\) = (\(x_i,y_i,2R_x, 2R_y, θ_i\))。然后我们可以计算 \(A_v\) 和 \(A_i\) 之间的重叠区域,即 \(P_{overlap}\) = Intersection(\(A_v\),\(A_i\))。然后对得到的 \(P_{overlap}\)(即多边形)进行下采样,以匹配特征地图 \(B_v\) ∈ \(R^{H×W ×C}\) 的大小. $\( \left.\mathbf{M}(i,j)=\left\{\begin{array}{cc}1&,&\mathrm{if~}(i,j)\in\mathbf{P}_{overlap}\\0&,&\mathrm{otherwise}\end{array}\right.\right. \)\( M(i, j) ∈ 0, 1 表示(i, j)坐标处的二进制值。通过只对非重叠区域 进行提炼,我们允许每个学生集中学习与各自领域一致的表征。这就避免了强制要求不完整的学生特征向教师的完整特征学习的严格约束 \)\( \begin{aligned} \mathcal{L}_{da}& =\mathcal{L}_1(\mathbf{B}_t,\mathbf{B}_v\odot\tilde{\mathbf{M}}_v)+\mathcal{L}_1(\mathbf{B}_t,\mathbf{B}_i\odot\tilde{\mathbf{M}}_i) \\ &=\frac1{HW}\sum_m^H\sum_m^W|\mathbf{B}_t(m,n)-\mathbf{B}_v(m,n)|\times\tilde{\mathbf{M}}_v(m,n) \\ &+\frac1{HW}\sum_m^H\sum_n^W|\mathbf{B}_t(m,n)-\mathbf{B}_i(m,n)|\times\tilde{\mathbf{M}}_i(m,n) \end{aligned} \)\( 在融合后的蒸馏,使用 DAF 模块有效地合并了来自不同领域的学生特征.因此,我们得到了一个能力很强的融合表征,用 Bf 表示,它可以与教师的特征表征 \)B_t$ 配对.
直观地说,Bt 是通过混合点云数据的早期协作获得的,其本质上涉及最小的信息损失.通过强制中间融合特征 \(B_f\) 逐步与\(B_t\) 保持一致,可以有效地确保在整个学习过程中始终整合通过早期融合阶段获得的基本知识,从而形成与领域无关的特征表征.
此外,我们还可以超越特征级对齐,扩展到预测级对齐.由于我们的最终目标是从两个 \(B_f\) 解码出最终的三维边界框,确保预测层面的对齐将进一步提高结果的一致性和准确性. $\( \begin{aligned} \mathcal{L}_{f}& =\mathcal{L}_1(\mathbf{B}_t,\mathbf{B}_f\odot\mathbf{M}_v) \\ &=\frac1{HW}\sum_m^H\sum_m^W|\mathbf{B}_t(m,n)-\mathbf{B}_f(m,n)|\times\tilde{\mathbf{M}}_v(m,n) \end{aligned} \)$
DAF 模块的目标是聚合车辆和基础设施的特征,创建一个包含各领域有价值信息的增强表示.然而,这一融合过程面临着两大挑战:双方姿势的潜在错位和设计合适的特征交互策略.

由于传感器噪声、动态运动和不同时间戳的不一致性等原因,现实世界中车辆和基础设施的相对姿态很容易受到影响,这将影响 V2X 感知的准确性.为了解决这个问题,利用校准偏移来动态纠正潜在的姿势误差.
首先用卷积层预测校准偏移,使\(B_i\)与\(B_v\)更好地对齐,记为 $\( \Delta_{(i\to v)}=\text{Conv}(\text{Concat}(\mathbf{B}_v,\mathbf{B}_i))\in\mathbb{R}^{H\times W\times2} \)$
空间自适应注意力可以通过聚合多粒度特征,提供稳健而灵活的注意力图
最后结果展示包括在两个数据集上与No fusion,early和late fusion以及一些列经典中期融合模型对比.
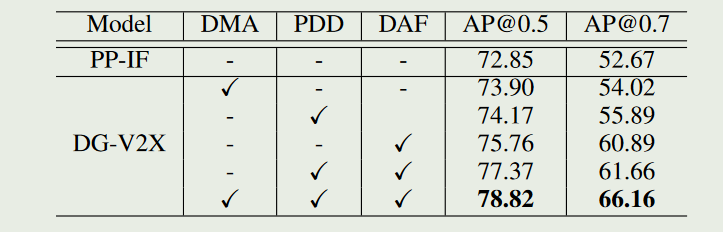
然后证明domain generalization实验证明模型学到了域不变的特征.辞海还有消融实验,证明提出的每个组件的作用.